Spatial Audio Capture
Each loudspeaker design has an analogous microphone design that operates on the same principles. Some examples of reciprocal systems are condenser microphones/electrostatic speakers, and dynamic microphones/magnetic coil loudspeakers. Panel loudspeakers are no different, and the sound waves generated by the human voice provide enough pressure to induce bending vibrations in a structure. These vibrations can be recorded by mounting one or more strain sensors or accelerometers to the active surface. Work in this area was primarily supported by a grant from the National Science Foundation. This allowed me to advise a number of research students including Tre DiPassio, who completed his Ph.D. in 2023, and Jenna Rutowski, who is a current Ph.D. student.
Challenges
Panel microphones are subject to the same design challenges as panel loudspeakers. The most problematic challenges as far as speech intelligibility is concerned are the long decay-times of isolated, low-frequency bending modes, which add reverberation to the signal. The impulse responses of nine panels (three sizes of three different materials) are shown below. The “aluminum” panel is two thin sheets of aluminum bonded with viscoelastic material, which greatly increases the amount of damping. The difference in audio quality between a panel mic and a conventional studio microphone is noticeable (see audio examples below). The speech transmission index (STI) score is reduced in panels with longer impulse responses. However, the recorded signal is intelligible, and the word-error-rate (WER) of IBM Watson’s speech-to-text service is only 3% worse than the studio microphone for even the most reverberant panels.


Direction of Arrival (DOA) Estimation
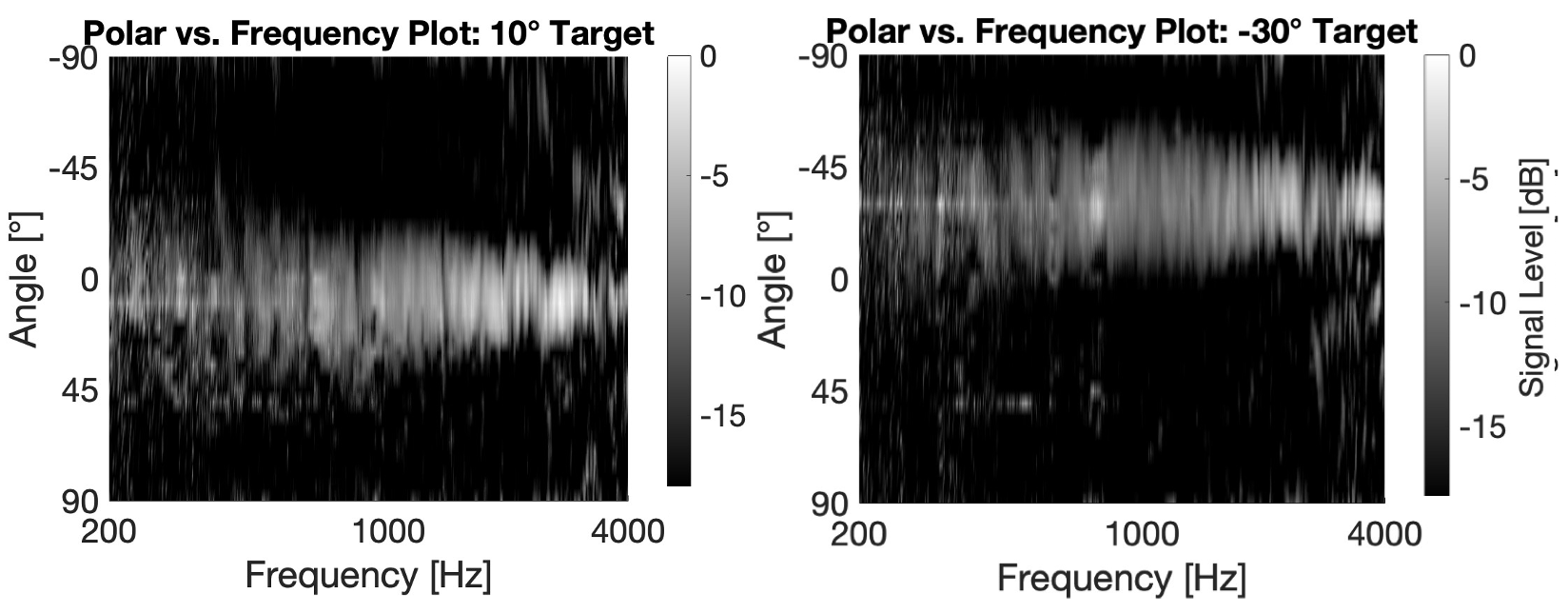
One benefit that arises from recording with a panel microphone is that the resonant modes of the surface provide spatial information about the audio source. Each resonant mode couples differently to an incident acoustic wave. So, by tracking the relative modal excitations, one can make an accurate estimate of the direction of the source. This can be done using just one sensor, as opposed to conventional DOA systems, which require a plurality of microphones. A basic proof of concept is illustrated below using a neural network to infer the directions of white noise bursts using a training set of noise bursts incident on the panel at 5° increments in the azimuthal plane across the front hemisphere. In this case, mel-frequency cepstral coefficients (MFCCs) were used as the feature set for training. Notice that output of the network is normally distributed around the ground truth angle. In this case, the acrylic panel performs better than the viscoelastically damped aluminum panel because the modal resonances are more pronounced.


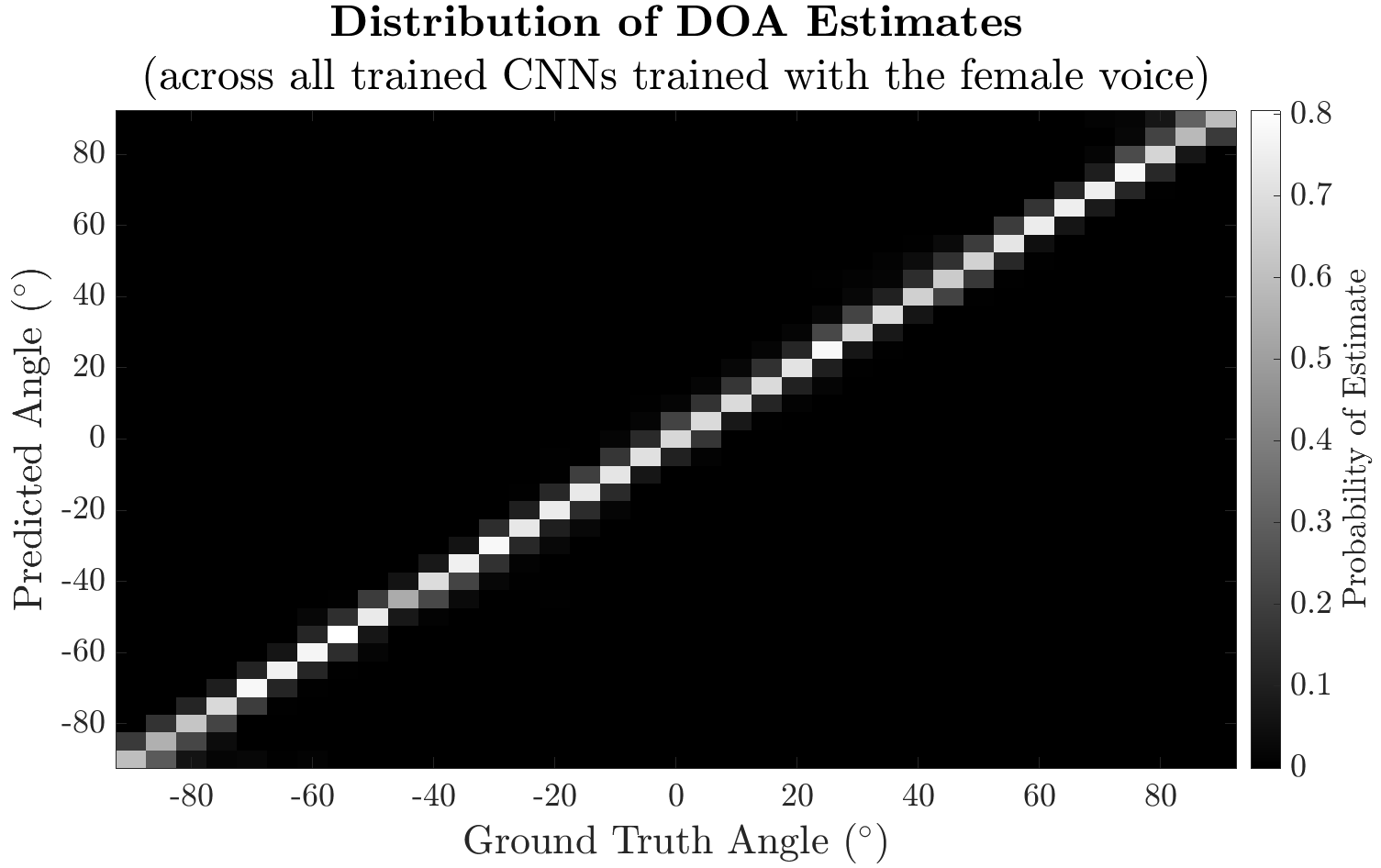
White noise bursts are an ideal excitation signal for this DOA method because they contain all frequencies, and are guaranteed to excite each mode if the mode shape couples to the angle of incidence. Resonant modes that provide significant spatial information about the source may not be excited by band-limited signals such as speech, causing a decrease in estimation accuracy. In general, plosives and fricatives are wide-band enough to excite the modes that provide significant spatial information as long as the panel is designed so that those modes lie within the speech bandwidth. The DOA system was shown to have high accuracy on the wake word phrase “Hey Alexa” for both male and female voices. More spectrally complete feature sets also provide more accurate estimations as shown in the table and confusion matrix below.

Duplex Mode Operation
If a panel were to operate as a loudspeaker and microphone simultaneously (as would be the case with a smart speaker) a system must be developed so that microphone can listen for a new voice command while playing music. Fortunately, the positions of both the force actuators driving the panel, and the vibration sensor(s) recording the vibrations are fixed, so the transfer function between them is constant as long as the panel operates in a linear regime. This transfer function can be applied to the known music signal, and then subtracted from the audio recorded by the vibration sensor to obtain the uncorrupted voice command. An example of this is shown below, where a panel records a speech signal while it is playing classical music. The system then removes the music recording to obtain the clean speech signal.


Acoustic Beamforming
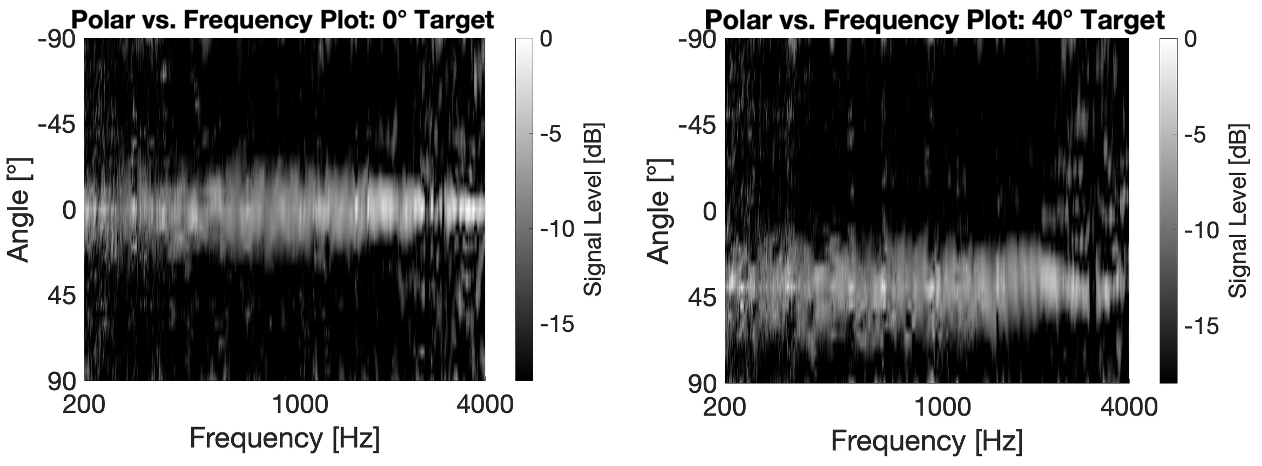
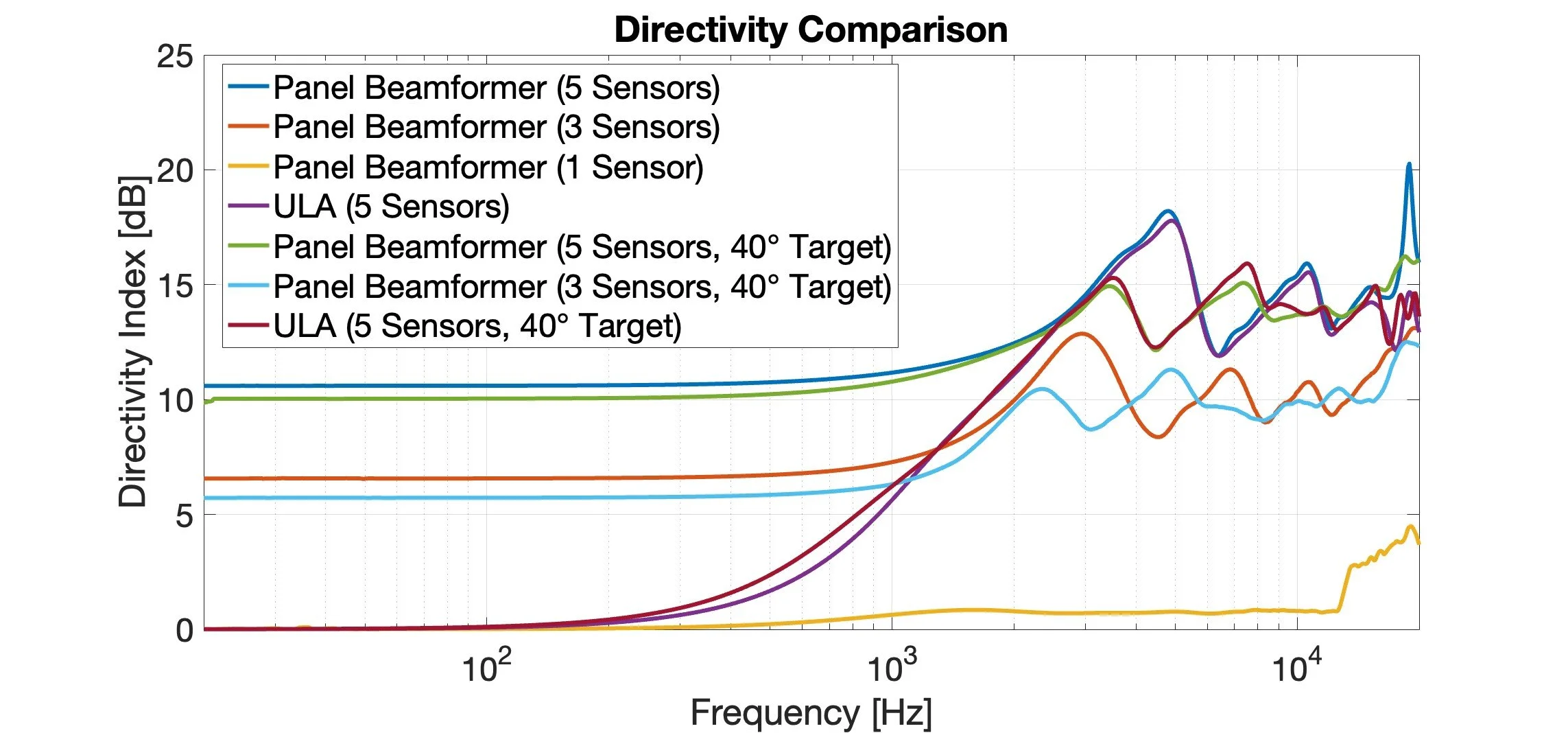
A steerable, wide-band beamformer can be made by coupling vibration sensors to an elastic panel. One can design filters to apply to each received sensor signal so that the sum of all the sensor signals achieves a target directional response. This is shown in the figure below (left) measured for a 5-sensor panel beamformer steered toward listening angles of 0° and 40°. The corresponding polar patterns at select frequencies are shown in the figure on the right for panels employing 1, 3 and 5 sensors along with a uniform line array (ULA) of conventional omnidirectional microphones.
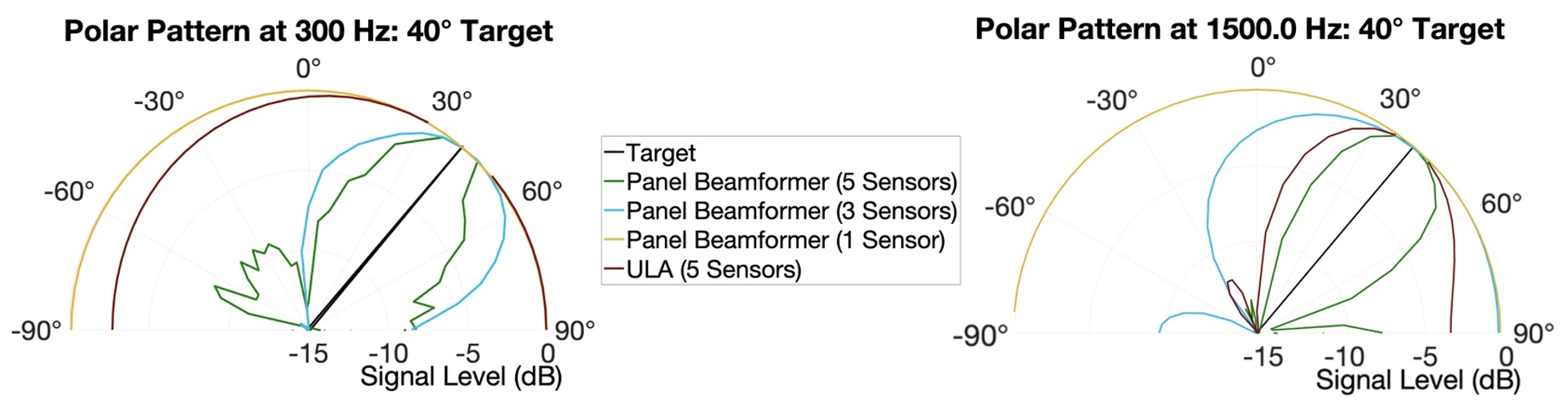
The panel beamformer is able to achieve an extended low-frequency bandwidth compared to an array of conventional microphones because of the coupling between the resonant modes and the incident acoustic wave. This allows for an extended low-frequency response compared to a ULA as shown in the figure above (right) and the directivity plot below. The system is not unlike the hearing system of the fly Ormia Ochracea, whose ears are coupled together by a small mechanical membrane, allowing it to localize sound sources at frequencies far below the spatial Nyquist rate of its ears. Prof. Ron Miles at SUNY Binghamton did some awesome work modeling the mechanics of this hearing system.
The use of resonances also allows the beamforming system to have more robust directional control. Conventional microphone arrays are limited to beamforming in the plane of the array geometry. However, panel beamformers do not see this restriction as long as the sensors are placed on points of the panel where they can detect the responses of the modes of interest. This is demonstrated in the figure below, where a panel employing a linear array of sensors in the azimuthal plane is able to steer a beam in the elevation plane, in this case down 30 degrees.